Metal MSM v2: Exploring MSM Acceleration on Apple GPUs

Key Takeaways
- Hybrid CPU-GPU approaches are essential for fully exploiting limited hardware such as mobile devices, improving MSM computation and accelerating proof generation.
- To unify GPU acceleration efforts, WebGPU's vendor-agnostic API and WGSL offer promising solutions that compile to native formats like SPIR-V (for Vulkan on Android) and MSL (for Metal on Apple devices).
- GPU acceleration for post-quantum proving systems could enable their widespread adoption.
Introduction
GPU acceleration harnesses the massive parallelism of Graphics Processing Units (GPUs) to dramatically speed up tasks that would otherwise overwhelm traditional CPUs. Because GPUs can execute thousands of threads simultaneously, they have become indispensable for compute-intensive workloads such as machine-learning model training and modern cryptographic algorithms.
This technology plays a crucial role in advancing privacy-preserving applications, as zero-knowledge proofs (ZKPs) currently face a significant bottleneck due to the high computational cost of their core operations. By accelerating these operations, we can generate proofs more quickly and cost-effectively, which is essential for the broader adoption of privacy-focused solutions across Ethereum and other blockchain platforms.
Currently, research on GPU acceleration for cryptography remains fragmented, with each platform relying on its own framework: Metal on Apple devices, Vulkan on Android, and CUDA on NVIDIA hardware. Aside from CUDA, most GPU frameworks lack mature ecosystems of cryptographic libraries (e.g., NVIDIA's cuPQC and cuFFT).
Therefore, Mopro is investing in GPU acceleration through related grants (Issue #21, Issue #22, and Issue #153), as it advances our mission to make mobile proving both accessible and practical.
A Primer on Multi-Scalar Multiplication
Multi-Scalar Multiplication (MSM) is an essential primitive in elliptic curve cryptography, particularly in pairing-based proving systems widely used for privacy-preserving applications. MSM involves computing a sum of the form , where are scalars and are points on an elliptic curve, such as BN254. This computationally intensive operation is ideal for GPU acceleration.
Metal MSM v2 is an open-source implementation, licensed under MIT and Apache 2.0, that optimizes MSM on Apple GPUs using the Metal Shading Language (MSL). Building on its predecessor, Metal MSM v2 offers significant performance improvements through algorithmic and GPU-specific optimizations, laying the foundation for further research into mobile proving acceleration with GPUs.
Recap on Metal MSM v1
The first version of Metal MSM (v1) was an initial attempt to bring MSM computations on the BN254 curve to Apple GPUs, leveraging parallelism and optimizations like precomputation from the EdMSM paper by Bootle et al.1. While it showed the potential for GPU acceleration, profiling result revealed key limitations:
- Low GPU Occupancy: At only 32%, the GPU was underutilized, leading to inefficient computation.
- High Memory Footprint: Peak VRAM usage was excessive, causing GPU hang errors on real mobile devices for instance sizes ≥ 2^14.
- Performance Bottlenecks: For an input size of 2^20 points, v1 took 41 seconds on an M1 Pro MacBook, indicating substantial room for improvement.
These challenges drove the development of a newer version, which introduces targeted optimizations to address these issues. For full context, refer to the detailed Metal MSM v1 Summary Report and Metal MSM v1 Profiling Report.
Metal MSM v2: What's New
Metal MSM v2 introduces key enhancements over v1, significantly improving performance and resource efficiency. It adopts the sparse matrix approach from the cuZK paper by Lu et al.2, treating MSM elements as sparse matrices to reduce memory usage and convert operations described in Pippenger's algorithm into efficient sparse matrix algorithms.
The implementation draws inspiration from Derei and Koh's WebGPU MSM implementation for ZPrize 2023. However, targeting the BN254 curve (unlike the BLS12-377 curve used by Zprize 2023) required different optimization strategies, particularly for Montgomery multiplications and for using Jacobian coordinates instead of projective or extended twisted Edwards coordinates.
Due to differences between shading languages (CUDA for cuZK, WGSL for WebGPU, and MSL for Metal), additional GPU programming efforts were necessary. For instance, dynamic kernel dispatching, which is straightforward in CUDA, required workarounds in Metal through host-side dispatching at runtime.
Key improvements include:
- Dynamic Workgroup Sizing: Workgroup sizes are adjusted based on input size and GPU architecture using a
scale_factorandthread_execution_width. These parameters were optimized through experimentation to maximize GPU utilization as mentioned in PR #86. - Dynamic Window Sizes: A window_size_optimizer calculates optimal window sizes using a cost function from the cuZK paper, with empirical adjustments for real devices, as detailed in PR #87.
- MSL-Level Optimizations: Loop unrolling and explicit access qualifiers, implemented in PR #88, enhance kernel efficiency, with potential for further gains via SIMD refactoring.
Benchmarks on an M3 MacBook Air with 24GB memory show 40x–100x improvements over v1 and ~10x improvement over ICME Labs' WebGPU MSM on BN254, adapted from Derei and Koh's BLS12-377 work. While still slower than CPU-only Arkworks MSM on small & medium input sizes, v2 lays the groundwork for a future CPU+GPU hybrid approach.
How Metal MSM v2 Works
The general flow follows Koh's technical writeup. We pack affine points and scalars on the CPU into a locality-optimized byte format, upload them to the GPU, and encode points into Montgomery form for faster modular multiplications. Scalars are split into signed chunks to enable the Non-Adjacent Form (NAF) method, halving both bucket count and memory during accumulation.
Next, we apply a parallel sparse-matrix transposition (adapted from Wang et al.'s work3) to identify matching scalar chunks and group points into buckets. Then, using a sparse-matrix–vector product (SMVP) and the pBucketPointsReduction algorithm (Algorithm 4 in the cuZK paper2), we split buckets among GPU threads, compute each thread's running sum, and scale it by the required factor.
After GPU processing, we transfer each thread's partial sums back to the CPU for final aggregation. Since the remaining point count is small and Horner's Method is sequential and efficient on the CPU, we perform the final sum there.
The use of sparse matrices is a key innovation in Metal MSM v2, reducing memory requirements and boosting parallelism compared to previous approaches.
Understanding the Theoretical Acceleration Upper Bound
In the Groth16 proving system, Number Theoretic Transform (NTT) and MSM account for 70–80% of the proving time. According to Amdahl's Law, the maximum speedup is limited by unoptimized components:
If 80% of the prover time is optimized with infinite speedup, the theoretical maximum is 5x. However, data I/O overhead reduces practical gains. For more details, see Ingonyama's blog post on Hardware Acceleration for ZKP.
Benchmark Results
Benchmarks conducted on an M3 MacBook Air compare Metal MSM v2 with the Arkworks v0.4.x CPU implementation across various input sizes.
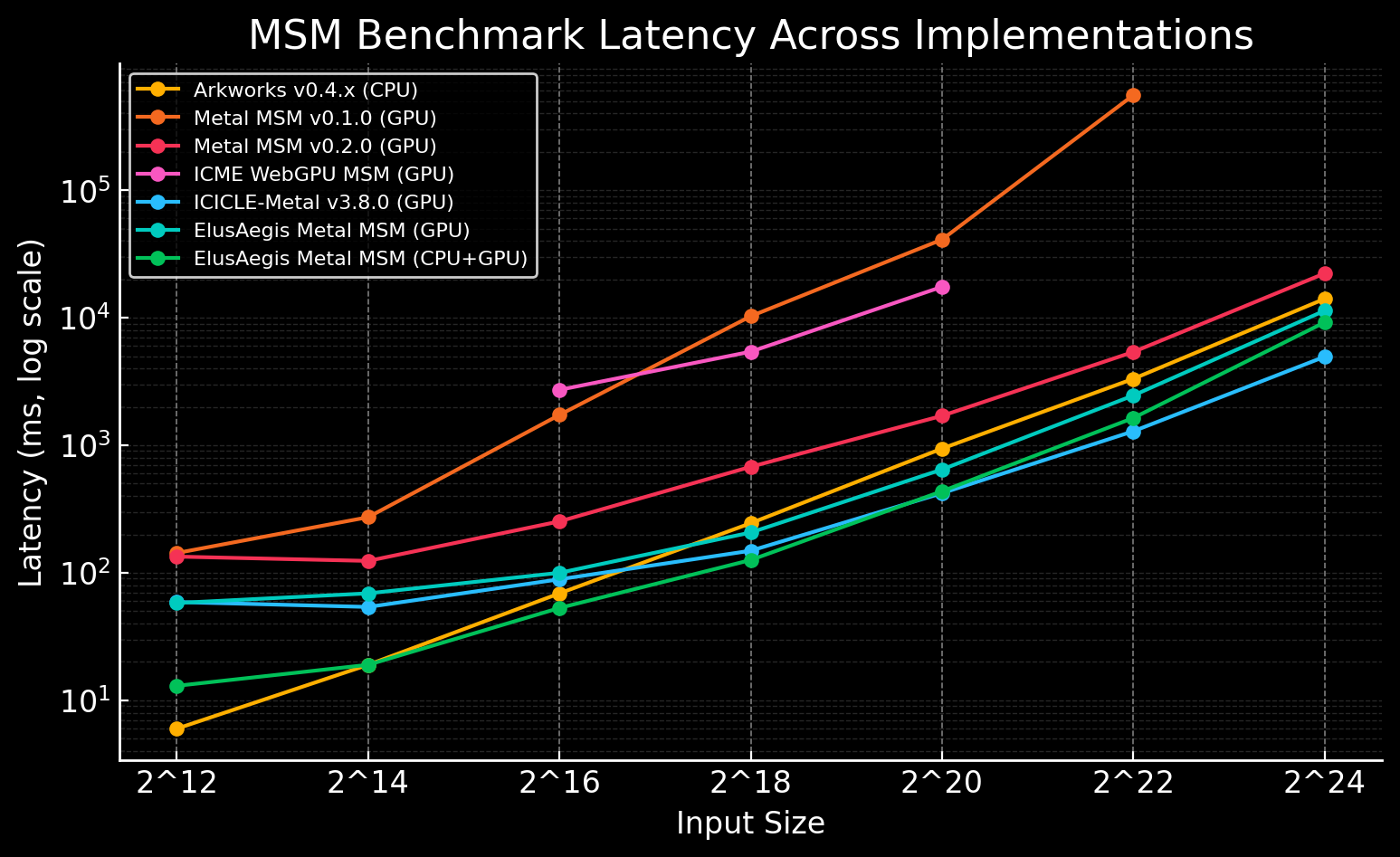
| Scheme | Input Size (ms) | ||||||
|---|---|---|---|---|---|---|---|
| 212 | 214 | 216 | 218 | 220 | 222 | 224 | |
| Arkworks v0.4.x (CPU, Baseline) | 6 | 19 | 69 | 245 | 942 | 3,319 | 14,061 |
| Metal MSM v0.1.0 (GPU) | 143 (-23.8x) | 273 (-14.4x) | 1,730 (-25.1x) | 10,277 (-41.9x) | 41,019 (-43.5x) | 555,877 (-167.5x) | N/A |
| Metal MSM v0.2.0 (GPU) | 134 (-22.3x) | 124 (-6.5x) | 253 (-3.7x) | 678 (-2.8x) | 1,702 (-1.8x) | 5,390 (-1.6x) | 22,241 (-1.6x) |
| ICME WebGPU MSM (GPU) | N/A | N/A | 2,719 (-39.4x) | 5,418 (-22.1x) | 17,475 (-18.6x) | N/A | N/A |
| ICICLE-Metal v3.8.0 (GPU) | 59 (-9.8x) | 54 (-2.8x) | 89 (-1.3x) | 149 (+1.6x) | 421 (+2.2x) | 1,288 (+2.6x) | 4,945 (+2.8x) |
ElusAegis' Metal MSM | 58 (-9.7x) | 69 (-3.6x) | 100 (-1.4x) | 207 (+1.2x) | 646 (+1.5x) | 2,457 (+1.4x) | 11,353 (+1.2x) |
ElusAegis' Metal MSM | 13 (-2.2x) | 19 (-1.0x) | 53 (+1.3x) | 126 (+1.9x) | 436 (+2.2x) | 1,636 (+2.0x) | 9,199 (+1.5x) |
Negative values indicate slower performance relative to the CPU baseline. The performance gap narrows for larger inputs.
Notes:
- For ICME WebGPU MSM, input size 2^12 causes M3 chip machines to crash; sizes not listed on the project's GitHub page are shown as "N/A"
- For Metal MSM v0.1.0, the 2^24 benchmark was abandoned due to excessive runtime.
While Metal MSM v2 isn't faster than CPUs across all hardware configurations, its open-source nature, competitive performance relative to other GPU implementations, and ongoing improvements position it well for continued advancement.
Profiling Insights
Profiling on an M1 Pro MacBook provides detailed insights into the improvements from v1 to v2:
| metric | v1 | v2 | gain |
|---|---|---|---|
| end-to-end latency | 10.3 s | 0.42 s | 24x |
| GPU occupancy | 32 % | 76 % | +44 pp |
| CPU share | 19 % | <3 % | –16 pp |
| peak VRAM | 1.6 GB | 220 MB | –7.3× |
These metrics highlight the effectiveness of v2's optimizations:
- Latency Reduction: A 24-fold decrease in computation time for 2^20 inputs.
- Improved GPU Utilization: Occupancy increased from 32% to 76%, indicating better use of GPU resources.
- Reduced CPU Dependency: CPU share dropped below 3%, allowing the GPU to handle most of the workload.
- Lower Memory Footprint: Peak VRAM usage decreased from 1.6 GB to 220 MB, a 7.3-fold reduction.
Profiling also identified buffer reading throughput as a primary bottleneck in v1, which v2 mitigates through better workload distribution and sparse matrix techniques. See detailed profiling reports: v1 Profiling Report and v2 Profiling Report.
Comparison to Other Implementations
Metal MSM v2 is tailored for Apple's Metal API, setting it apart from other GPU-accelerated MSM implementations:
- Derei and Koh's WebGPU MSM on BLS12: Designed for WebGPU, this implementation targets browser-based environments and may not fully leverage Apple-specific hardware optimizations.
- ICME labs WebGPU MSM on BN254: Adapted from Derei and Koh's WebGPU work for the BN254 curve, it is ~10x slower than Metal MSM v2 for inputs from 2^16 to 2^20 on M3 MacBook Air.
- cuZK: A CUDA-based implementation for NVIDIA GPUs, operating on a different hardware ecosystem and using different algorithmic approaches.
Metal MSM v2's use of sparse matrices and dynamic workgroup sizing provides advantages on Apple hardware, particularly for large input sizes. While direct benchmark comparisons are limited, internal reports suggest that v2 achieves performance on par with or better than other WebGPU/Metal MSM implementations at medium scales.
It's worth noting that the state-of-the-art Metal MSM implementation is Ingonyama's ICICLE-Metal (since ICICLE v3.6). Readers can try it by following:
Another highlight is ElusAegis' Metal MSM implementation for BN254, which was forked from version 1 of Metal MSM. To the best of our knowledge, his pure GPU implementation further improves the allocation and algorithmic structure to add more parallelism, resulting in 2x faster performance compared to Metal MSM v2.
Moreover, by integrating this GPU implementation with optimized MSM on the CPU side from the halo2curves library, he developed a hybrid approach that splits MSM tasks between CPU and GPU and then aggregates the results. This strategy achieves an additional 30–40% speedup over a CPU-only implementation. This represents an encouraging result for GPU acceleration in pairing-based ZK systems and suggests a promising direction for Metal MSM v3.
Future Work
The Metal MSM team has outlined several exciting directions for future development:
- SIMD Refactoring: Enhance SIMD utilization and memory coalescing to further boost performance.
- Advanced Hybrid Approach: Integrate with Arkworks 0.5 for a more sophisticated CPU-GPU hybrid strategy.
- Android Support: Port kernels to Vulkan compute/WebGPU on Android, targeting Qualcomm Adreno (e.g., Adreno 7xx series) and ARM Mali (e.g., G77/G78/G710) GPUs.
- Cross-Platform Support: Explore WebGPU compatibility to enable broader platform support.
- Dependency Updates: Transition to newer versions of objc2 and objc2-metal, and Metal 4 to leverage the latest MTLTensor features, enabling multi-dimensional data to be passed to the GPU.
Beyond these technical improvements, we are also interested in:
- Exploration of PQ proving schemes: With the limited acceleration achievable from pairing-based proving schemes, we're motivated to explore PQ-safe proving schemes that have strong adoption potential over the next 3–5 years. These schemes, such as lattice-based proofs, involve extensive linear algebra operations that can benefit from GPUs' parallel computing capabilities.
- Crypto Math Library for GPU: Develop comprehensive libraries for cryptographic computations across multiple GPU frameworks, including Metal, Vulkan, and WebGPU, to expand the project's overall scope and impact.
Conclusion
Metal MSM v2 represents a leap forward in accelerating Multi-Scalar Multiplication on Apple GPUs. By addressing the limitations of v1 through sparse matrix techniques, dynamic thread management, and other novel optimization techniques, it achieves substantial performance gains for Apple M-series chips and iPhones.
However, two challenges remain:
- First, GPUs excel primarily with large input sizes (typically around 2^26 or larger). Most mobile proving scenarios use smaller circuit sizes, generally ranging from 2^16 to 2^20, which limits the GPU's ability to fully leverage its parallelism. Therefore, optimizing GPU performance for these smaller workloads remains a key area for improvement.
- Second, mobile GPUs inherently possess fewer cores and comparatively lower processing power than their desktop counterparts, constraining achievable performance. This hardware limitation necessitates further research into hybrid approaches and optimization techniques to maximize memory efficiency and power efficiency within the constraints of mobile devices.
Addressing these challenges will require ongoing algorithmic breakthroughs, hardware optimizations, and seamless CPU–GPU integration. Collectively, these efforts pave a clear path for future research and practical advancements that enable the mass adoption of privacy-preserving applications.
Get Involved
We welcome researchers and developers interested in GPU acceleration, cryptographic computations, or programmable cryptography to join our efforts:
- GPU Exploration Repository (latest version includes Metal MSM v2)
- Mopro (Mobile Proving)
For further inquiries or collaborations, feel free to reach out through the project's GitHub discussions or directly via our Mopro community on Telegram.
Special Thanks
We extend our sincere gratitude to Yaroslav Yashin, Artem Grigor, and Wei Jie Koh for reviewing this post and for their valuable contributions that made it all possible.
Footnotes
-
Bootle, J., & Chiesa, A., & Hu, Y. (2022). "Gemini: elastic SNARKs for diverse environments." IACR Cryptology ePrint Archive, 2022/1400: https://eprint.iacr.org/2022/1400 ↩
-
Lu, Y., Wang, L., Yang, P., Jiang, W., Ma, Z. (2023). "cuZK: Accelerating Zero-Knowledge Proof with A Faster Parallel Multi-Scalar Multiplication Algorithm on GPUs." IACR Cryptology ePrint Archive, 2022/1321: https://eprint.iacr.org/2022/1321 ↩ ↩2
-
Wang, H., Liu, W., Hou, K., Feng, W. (2016). "Parallel Transposition of Sparse Data Structures." Proceedings of the 2016 International Conference on Supercomputing (ICS '16): https://synergy.cs.vt.edu/pubs/papers/wang-transposition-ics16.pdf ↩